


名称
解释器模式(INTERPRETER)
目的
给定一个语言,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子
适用性
当有一个语言需要解释执行,并且可以将该语言中的句子表示为一个抽象语法树时,可使用解释器模式。当存在以下情况时该模式效果最好:
该文法简单,对于复杂的文法,文法的类层次变得庞大而无法管理。此时语法分析程序生成器这样的工具是更好的选择。它们无需构建抽象语法树即可解释表达式,这样可以节省空间而且还可能节省时间。
效率不是一个关键问题。最高效的解释器通常不是通过直接解释语法分析树实现的,而是首先将它们转换成另一种形式。例如,正则表达式通常被转换成状态机。但即使在这种情况下,转换器仍可用解释器模式实现,该模式仍是有用的。
结构
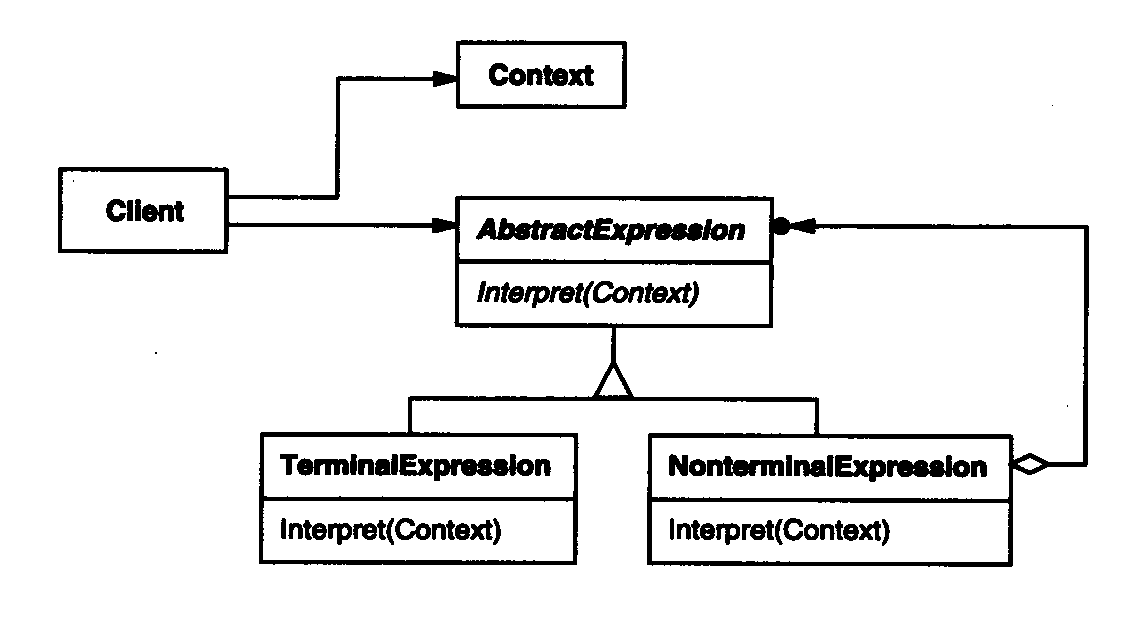
抽象表达式(AbstractExpression):声明一个抽象的解释操作,这个接口为抽象语法树中所有的节点所共享。
终结符表达式(TerminalExpression):
实现与文法中的终结符相关联的解释操作。
一个句子中的每个终结符需要该类的一个实例。
终结符表达式是解析树中最基本的元素,它们通常是不可再分的最小单位。在解释器模式中,终结符表达式通常对应于文法中的叶子节点,如关键字(如public)、标识符、数字(如 3, 4)、操作符(如 +, -, *, /)等。
非终结符表达式(NonterminalExpression):
对文法中的每一条规则R::=R1R2……Rn都需要一个NonterminalExpression类。
为从R1到Rn的每个符号都维护一个AbstractExpression类型的实例变量。
为文法中的非终结符实现解释(Interpret)操作。解释(Interpret)一般要递归地调用表示R1到Rn的那些对象的解释操作。
非终结符表达式是通过组合多个终结符表达式和其他非终结符表达式形成的复杂表达式。它们通常对应于文法中的非叶子节点,负责定义如何组合子表达式来形成更大的表达式或语句。如:加法表达式 (3 + 4)、乘法表达式 (3 * 4)、复杂的嵌套表达式 ((3 + 4) * 2)
上下文(Content):包含解释器之外的一些全局信息。在解释过程中提供给解释器使用,通常用于存储变量的值、保存解释器的状态等。
客户端(Client):
构建(或被给定)表示该文法定义的语言中一个特定的句子的抽象语法树。该抽象语法树由NonterminalExpression和TerminalExpression的实例装配而成。
调用解释操作。
协作
Client构建(或被给定)一个句子,它是NonterminalExpression和TerminalExpression的实例的一个抽象语法树。然后初始化上下文并调用解释操作。
每一非终结符表达式节点定义相应子表达式的解释操作。而各终结符表达式的解释操作构成了递归的基础。
每一节点的解释操作用上下文来存储和访问解释器的状态。
效果
优点
易于改变和扩展文法。因为该模式使用类来表示文法规则 , 可以使用继承来改变或扩展该文法。已有的表达式可被增量式地改变 ,而新的表达式可定义为旧表达式的变体。
易于实现文法。定义抽象语法树中各个节点的类的实现大体类似。这些类易于直接编写,通常它们也可用一个编译器或语法分析程序生成器自动生成。
缺点
对于复杂的文法难以维护。解释器模式为文法中的每一条规则至少定义了一个类(使用BNF定义的文法规则需要更多的类),因此包含许多规则的文法可能难以管理和维护,可应用其他的设计模式来缓解这一问题。但是当文法非常复杂时,其他的技术如语法分析程序或编译器生成器更为合适。
执行效率较低。解释器模式中通常使用大量的循环和递归调用来解释句子,当要解释的句子较复杂时,其运行速度可能会很慢。
引起类膨胀。解释器模式中的每条规则至少需要定义一个类,当包含的文法规则很多时,类的数量会急剧增加,导致系统难以管理和维护。
可应用的场景较少。在软件开发中,需要定义语言文法的应用实例相对较少,因此这种模式并不常用。
实现
创建语法树。解释器模式并未解释如何创建一个抽象的语法树。换言之,它不涉及语法分析。抽象语法树可用一个表驱动的语法分析程序来生成,也可用手写的(通常为递归下降法)语法分析程序创建,或直接由Client提供。
定义解释操作。并不一定要在表达式类中定义解释操作。如果经常要创建一种新的解释器,那么使用观察者模式将解释放入一个独立的“访问者”对象更好一些。例如。一个程序设计语言的会有许多在抽象语法树上的操作,比如类型检查、优化、代码生成,等等。恰当的做法是使用一个访问者以避免在每一个类上都定义这些操作。
与Flyweight模式共享终结符。在一些文法中,一个句子可能多次出现同一个终结符,此时最好共享那个符号的单个拷贝。
应用
问题
解释器的目的就是解释语言中的句子,假设我们设计一种语言javaCalculate,这个语言是基于java实现的,这个时候就需要解释器根据javaCalculate的语法去解释为java语言,并调用java语言实现javaCalculate的功能。这里我们可以使用解释器实现javaCalculate的乘法、除法、取余的计算,根据解释器原理,我们要把javaCalculate语言中的语句分解成各个节点(抽象),形成语法树,语法树中的节点有终结符表达式和非终结符表达式,根据这两种表达式的语义,数字和运算符都是终结符表达式,数字和运算符的组合节点是非终结符表达式。
我们抽象出一个语法节点Node,它定义了一个方法interpret()用于解释javaCalculate的语法;定义一个值节点ValueNode用于存放语言中的值value,ValueNode节点实现Node并重写方法interpret()(返回value的值);定义一个符号节点SymbolNode(抽象类,不用去实现方法)用于存储运算符的左右节点,具体是什么运算符由它的子节点DivNode、ModNode、MulNode决定,并且这些字节点也重写方法interpret()(使用java运算后并返回值);以上节点构成了javaCalculate语言中计算功能的语法树和解释方法,但是我们还需要两个操作就是构建语法树和执行解释,所以我们定义一个计算器作为上下文,其中有一个语法树节点用于存储语法树,同时定义了构建语法树和执行解释的方法(build()和compute(),具体实现方式在代码中有详细注释),然后使用客户端测试解释器对javaCalculate语法的解释执行。
示例
UML
代码示例
抽象表达式:语法节点
package com.ysj.part5.interpreter.abstractExpression;
/**
* 抽象表达式:语法节点
*/
public interface Node {
public int interpret();
}终结符表达式:值节点,实现语法节点
package com.ysj.part5.interpreter.terminalExpression;
import com.ysj.part5.interpreter.abstractExpression.Node;
/**
* 终结符表达式:数字节点
*/
public class ValueNode implements Node {
/**
* 数值
*/
private int value;
public ValueNode(int value) {
this.value = value;
}
public int interpret() {
return this.value;
}
}非终结符表达式:运算符节点(抽象类)实现语法节点,定义属性左右节点,以及运算符节点的子类除法节点、取余节点、乘法节点,实现interpret()方法
package com.ysj.part5.interpreter.nonTerminalExpression;
import com.ysj.part5.interpreter.abstractExpression.Node;
/**
* 非终止符节点:符号节点(主要目的是提取出运算符节点都有的公共状态,即左右节点)
*/
public abstract class SymbolNode implements Node {
/**
* 左节点
*/
protected Node left;
/**
* 右节点
*/
protected Node right;
public SymbolNode(Node left, Node right) {
this.left = left;
this.right = right;
}
}package com.ysj.part5.interpreter.nonTerminalExpression;
import com.ysj.part5.interpreter.abstractExpression.Node;
/**
* 非终止符节点:除法节点
*/
public class DivNode extends SymbolNode {
public DivNode(Node left, Node right) {
super(left, right);
}
public int interpret() {
return super.left.interpret() / super.right.interpret();
}
}package com.ysj.part5.interpreter.nonTerminalExpression;
import com.ysj.part5.interpreter.abstractExpression.Node;
/**
* 非终止符节点:取余节点
*/
public class ModNode extends SymbolNode {
public ModNode(Node left, Node right) {
super(left, right);
}
public int interpret() {
return super.left.interpret() % super.right.interpret();
}
}package com.ysj.part5.interpreter.nonTerminalExpression;
import com.ysj.part5.interpreter.abstractExpression.Node;
/**
* 非终止符节点:乘法节点
*/
public class MulNode extends SymbolNode {
public MulNode(Node left, Node right) {
super(left, right);
}
public int interpret() {
return left.interpret() * right.interpret();
}
}上下文:计算器,使用Node存储语法树节点,使用build()构建语法树,使用compute()解释执行,具体实现细节看代码内注释。
package com.ysj.part5.interpreter.context;
import com.ysj.part5.interpreter.abstractExpression.Node;
import com.ysj.part5.interpreter.terminalExpression.ValueNode;
import com.ysj.part5.interpreter.nonTerminalExpression.DivNode;
import com.ysj.part5.interpreter.nonTerminalExpression.ModNode;
import com.ysj.part5.interpreter.nonTerminalExpression.MulNode;
import java.util.Stack;
/**
* 上下文:计算器
*/
public class Calculator {
/**
* 节点
*/
private Node node;
/**
* 构建语法树
* @param statement
*/
public void build(String statement) {
// 定义左节点和右节点
Node left = null, right = null;
// 定义栈,因为栈是先入后出的数据结构,与函数的调用顺序一致,可以做到先近栈的后调用,所以用来存储语法树
Stack<Node> stack = new Stack<Node>();
// 拆分语句,使用“ “作为分割符
String[] statementArr = statement.split(" ");
/*
* 遍历语句中的节点(值节点是终结符表达式,运算符节点是把左右值节点连接起来的非终结符表达式),根据不同的节点,做不同的处理。
* 总体思路:从左到右存储各节点,遇到值节点,直接入栈;遇到运算符节点,从栈中取出之前存的节点,作为左节点,
* 运算符右边的值节点作为右节点,使用运算符节点(如:乘、除、余)将左右节点装入作为一个新的节点,再入栈。
* 以“3 * 2 * 4 / 6 % 5”为例:
* 第一次遍历时,i=0,节点3是值节点,直接入栈;
* 第二次遍历时,i=1,节点*是运算符节点,从栈中取出最新的节点(也就是3),把左右的终结符表达式使用非终结符表达式联结后再放入栈中,此时栈中为(3 * 2);
* 第三次遍历时,i=3,节点*是运算符节点,从栈中取出最新的节点(也就是3 * 2),把左右的终结符表达式使用非终结符表达式联结后再放入栈中,此时栈中为(3 * 2 )* 4;
* 第四次遍历时,i=5,节点/是运算符节点,从栈中取出最新的节点(也就是3 * 2 )* 4,把左右的终结符表达式使用非终结符表达式联结后再放入栈中,此时栈中为((3 * 2 )* 4 )/ 6;
* 第五次遍历时,i=7,节点%是运算符节点,从栈中取出最新的节点(也就是((3 * 2 )* 4 )/ 6),把左右的终结符表达式使用非终结符表达式联结后再放入栈中,此时栈中为(((3 * 2 )* 4 )/ 6)% 5;
* 遍历完后,将栈中的节点取出,即为最终结果。
* 注意:栈中存储的节点一直都只有0个或1个,数据是以树状结构存储在节点中。
*/
for (int i = 0; i < statementArr.length; i++) {
if (statementArr[i].equalsIgnoreCase("*")) {
//终结符表达式 先从栈取出最新的(也是唯一的),把左右的非终结符表达式使用终结符表达式联结后再放入栈中
left = stack.pop();
int val = Integer.parseInt(statementArr[++i]);
right = new ValueNode(val);
stack.push(new MulNode(left, right));
} else if (statementArr[i].equalsIgnoreCase("/")) {
left = stack.pop();
int val = Integer.parseInt(statementArr[++i]);
right = new ValueNode(val);
stack.push(new DivNode(left, right));
} else if (statementArr[i].equalsIgnoreCase("%")) {
left = stack.pop();
int val = Integer.parseInt(statementArr[++i]);
right = new ValueNode(val);
stack.push(new ModNode(left, right));
} else {
//非终结符表达式 直接放入栈
stack.push(new ValueNode(Integer.parseInt(statementArr[i])));
}
}
this.node = stack.pop();
}
/**
* 计算
* @return
*/
public int compute() {
/*
* 语法树计算,即递归调用各节点的 interpret()方法,计算最终结果。
* 语法树计算过程:
* 第一次调用:根节点为(((3 * 2 )* 4 )/ 6)% 5,调用根节点的 interpret()方法,右节点为值节点,直接得到值为5;左节点是除法节点((3 * 2 )* 4 )/ 6),调用的是除法节点的 interpret()方法。
* 第二次调用:根节点为(((3 * 2 )* 4 )/ 6),调用根节点的 interpret()方法,右节点为值节点,直接得到值为6;左节点是乘法节点((3 * 2 )* 4),调用的是乘法节点的 interpret()方法。
* 第三次调用:根节点为((3 * 2 )* 4),调用根节点的 interpret()方法,右节点为值节点,直接得到值为4;左节点是乘法节点(3 * 2),调用的是乘法节点的 interpret()方法。
* 第四次调用:根节点为(3 * 2),调用根节点的 interpret()方法,右节点为值节点,直接得到值为2;左节点也是值节点,直接得到值为3。
* 至此,递归调用完结。最终结算结果为4。
* 总的来说就是:从根节点开始,递归调用各节点的 interpret()方法,interpret()的具体实现中,右节点是值节点直接得出,左节点要一直递归,直至左节点是值节点跳出。
*/
return node.interpret();
}
}客户端:调用方
package com.ysj.part5.interpreter;
import com.ysj.part5.interpreter.context.Calculator;
/**
* 解释器模式
* 给定一个语言,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子
*/
public class Client {
public static void main(String args[]) {
// 定义执行语句
String statement = "3 * 2 * 4 / 6 % 5";
// 创建上下文对象
Calculator calculator = new Calculator();
// 构建语法树,结构为Calculator中node
calculator.build(statement);
// 执行解释操作,并获取运算结果
int result = calculator.compute();
// 打印结果
System.out.println(statement + " = " + result);
}
}已知应用
JavaCC
JavaCC 是 Sun Microsystems 开发的一个解析器生成器,用于生成 Java 语言的词法分析器和语法分析器。


评论区