


认识jvm
java程序运行步骤
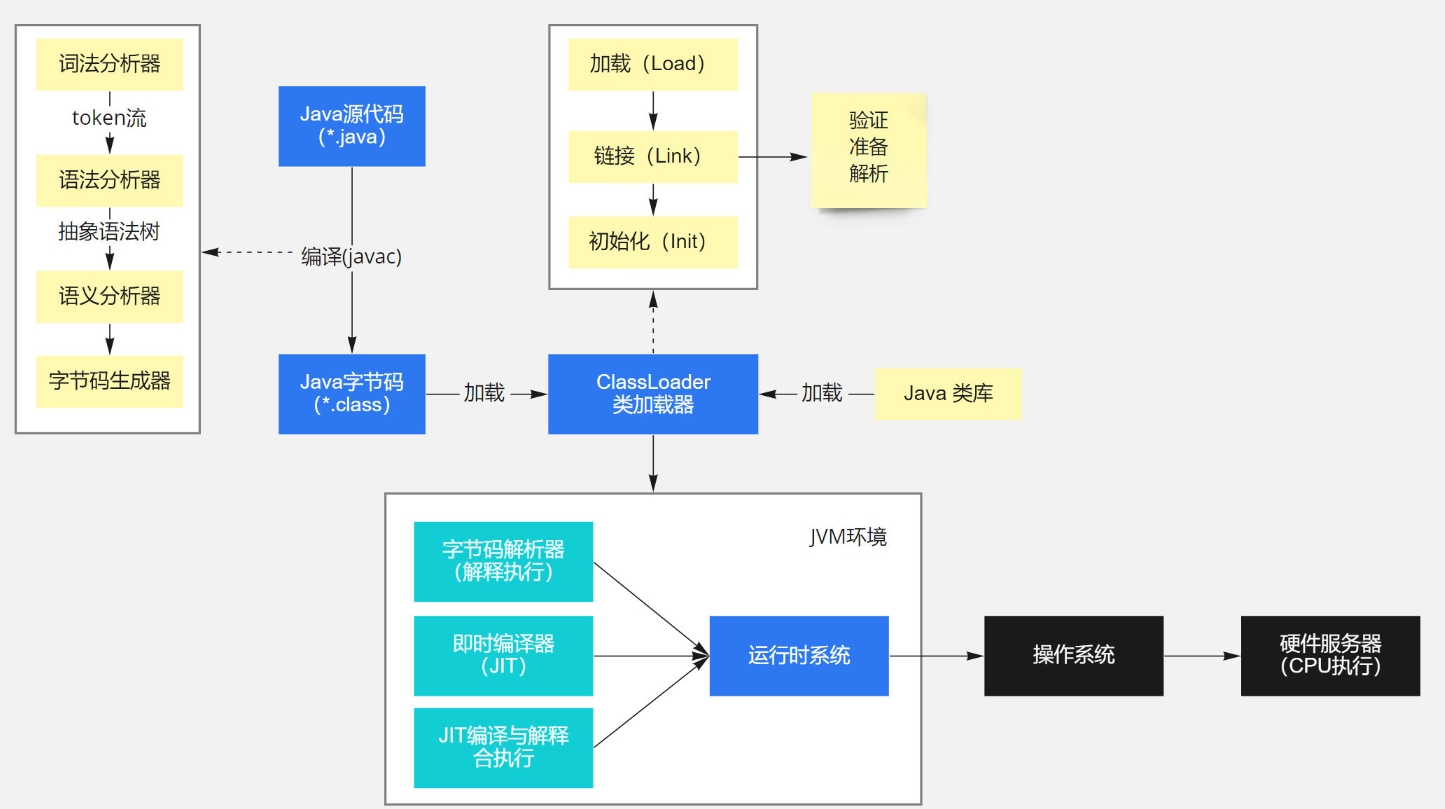
编译阶段
词法分析:
编译器会逐个字符地读取代码文本。
将连续的字符组合识别为有意义的词法单元,如关键字(如 public、class 等)、标识符(变量名、方法名等)、常量(数字、字符串等)、运算符(+、-、*、/ 等)以及各种分隔符(如括号、分号等)。
这些词法单元被标记并分类,形成一个有序的词法单元序列。
语法分析:
基于词法单元序列,根据 Java 语言定义的语法规则,构建一棵抽象语法树(AST)。
AST 以树状结构表示代码的语法结构,节点代表各种语法元素,如类声明、方法定义、表达式等。
语法分析器会检查代码是否符合 Java 语法的正确组合和嵌套关系。
语义分析:
对 AST 进行更深入的分析,检查语义的正确性。
包括变量的声明和使用是否匹配、类型是否正确、方法调用的参数是否合法等。
还会进行一些复杂的语义检查,如继承关系的合法性、多态性的处理等。
字节码生成:
基于经过语义分析后的 AST,编译器将代码转换为字节码指令。
为每个方法、类等生成相应的字节码序列。
同时,会处理一些细节,如生成常量池,包含字符串常量、类和方法的引用等信息。
最终生成对应的字节码文件(.class 文件),每个类都有自己独立的字节码文件。
运行阶段
启动 JVM:
用户执行 Java 程序时,操作系统会启动 JVM 进程。
JVM 会进行一系列的初始化操作,包括设置内存区域、加载一些核心类等。
类加载:
JVM 中的类加载器负责加载需要执行的类的字节码文件。
它首先会检查类是否已经加载,如果没有,则从特定的位置(如类路径)读取字节码文件并加载到内存中。
加载过程包括解析字节码文件,创建对应的类对象,并将其存储在方法区。
字节码执行:
JVM 的执行引擎负责执行字节码指令。
执行引擎可以采用不同的执行方式,如解释执行或即时编译(JIT)。
解释执行是逐行解释字节码并执行相应操作;JIT 会在运行时将热点代码编译成本地机器码以提高执行效率。
执行过程中涉及到各种操作,如算术运算、逻辑判断、方法调用、对象创建等。
对于方法调用,会根据方法的具体实现执行相应的代码。
内存管理:
JVM 将内存划分为多个区域,如堆用于存储对象实例,栈用于方法调用和局部变量等。
它会进行内存分配,当对象不再使用时进行垃圾回收,以释放内存空间。
内存管理机制确保程序在运行时有足够的内存可用,同时避免内存泄漏和无效的内存访问。
与操作系统交互:
当需要进行输入输出、网络通信等操作时,JVM 通过特定的接口与操作系统交互。
操作系统提供了底层的资源和服务,JVM 调用这些功能来完成实际的操作。
java的跨平台特性
不同的操作系统和硬件平台都有各自对应的 JVM 实现。JVM 负责解释执行字节码或者在运行时进行即时编译(JIT)将其转换为本地机器码。JVM 屏蔽了底层硬件和操作系统的差异,使得字节码可以在不同平台上的 JVM 中以相同的方式运行。
JVM 提供了运行 Java 程序所需的运行时环境,包括内存管理、线程调度、安全机制等。这些功能在不同平台上由 JVM 实现,保证了程序运行的一致性和稳定性。
java中的jvm
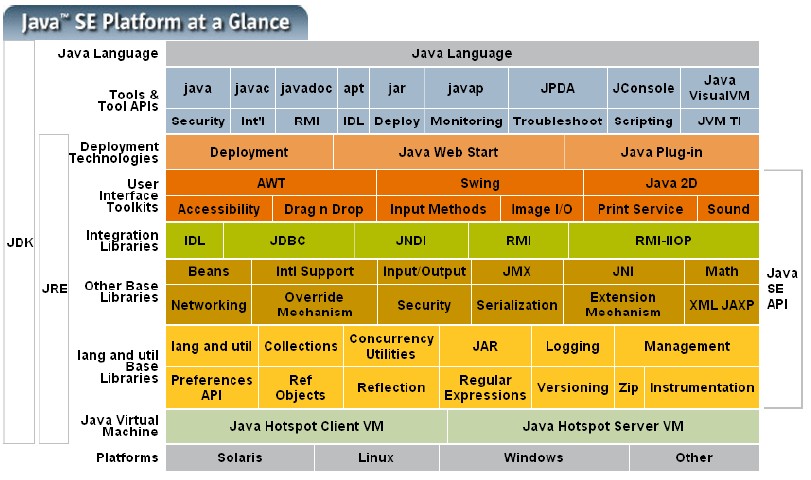
可以看出jdk是包含jre,jre是包含jvm的。
jvm是 Java 程序能够跨平台运行的核心。JDK 用于开发,JRE 用于运行。
jvm负责加载字节码并执行,提供了内存管理、线程调度等基础功能,将字节码解释或编译成本地机器指令来执行。
jvm结构
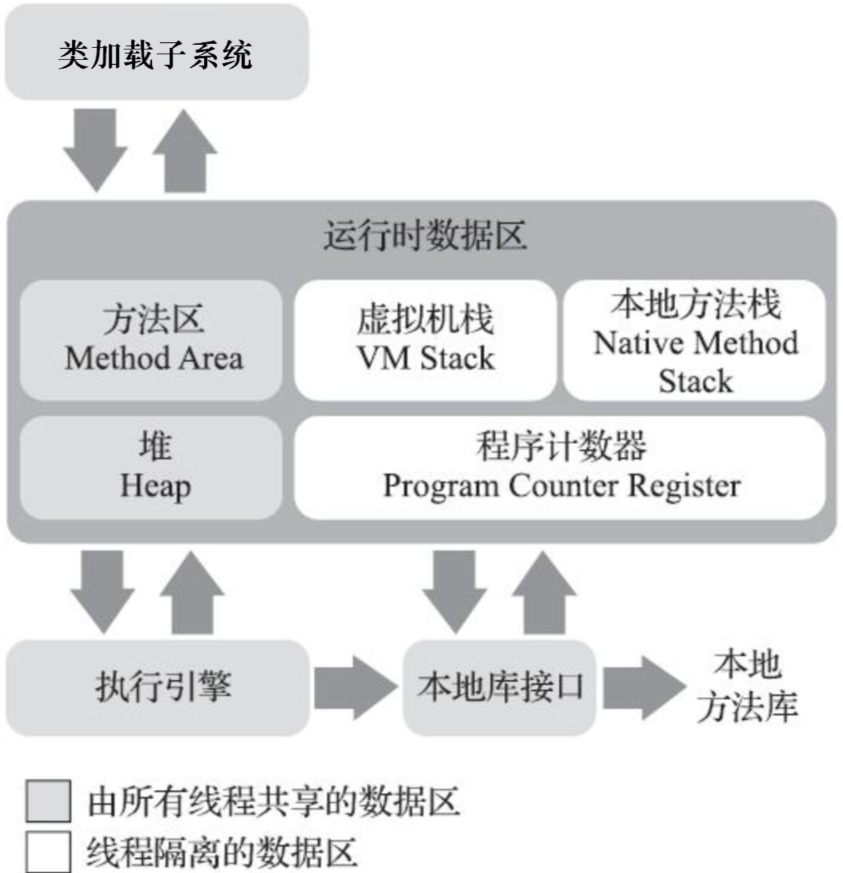
类加载器
类加载器(ClassLoader)主要负责将字节码文件加载到内存中并创建对应的类对象。(详细内容会单独出一章进行讲解)
运行时数据区
运行时数据区(Runtime Data Area)是 Java 程序在运行时所使用的内存区域。
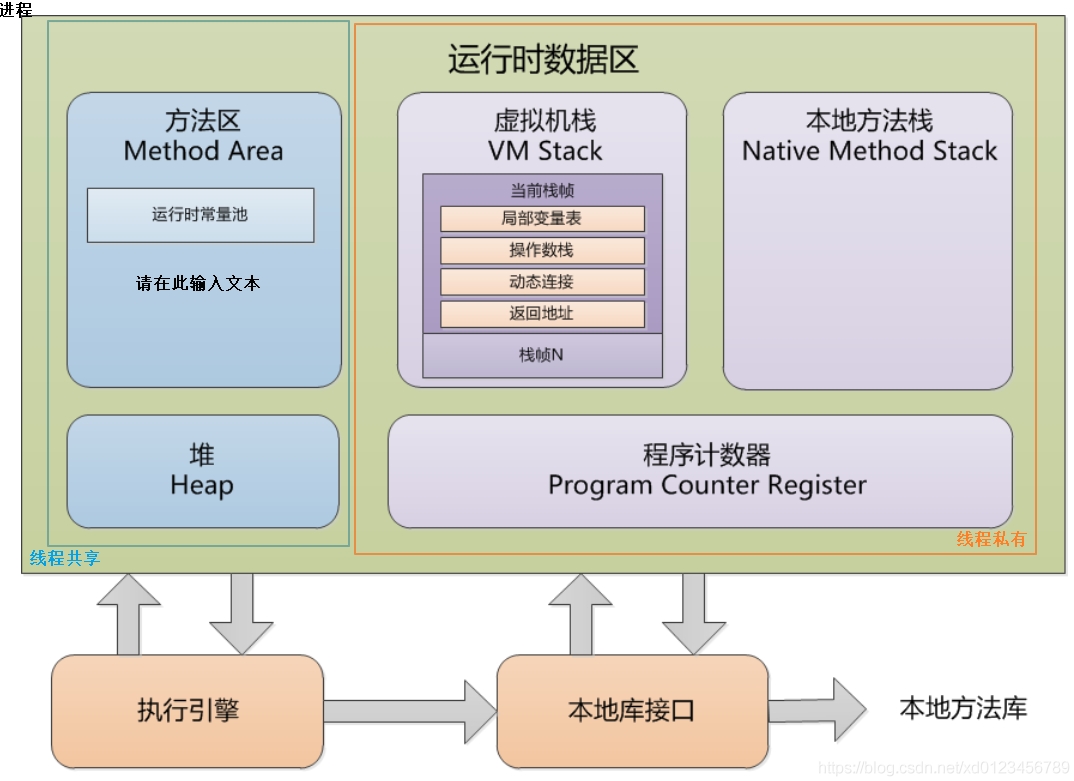 蓝色矩形内的线程共享,红色矩形内的线程私有
蓝色矩形内的线程共享,红色矩形内的线程私有
方法区
方法区(Method Area)是线程共享的内存区域,主要用于存储类信息、常量池、字段信息、方法信息,从java8开始被废弃,由元空间替代。
它有个别命叫非堆(Non-Heap)。当方法区无法满足内存分配需求时,会抛出OutOfMemoryError异常。
类信息:包括类的名称、访问修饰符、类的类型(如普通类、接口等)、父类信息等。
常量池:存放编译期生成的字面量(如字符串常量、数字常量等)和符号引用(类和方法的全限定名等)。运行期也可能将新的常量放入池中,这种特性被开发人员利用得比较多的便是String类的intern()方法。
字段信息:每个类的字段相关信息,如字段名称、类型、修饰符等。
方法信息:每个方法的信息,包括方法名称、返回类型、参数列表、修饰符以及方法字节码等。
Java堆
java堆(Java Heap)是java虚拟机所管理的内存中最大的一块,是被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例和数组(java虚拟机规范中的描述:所有的对象实例以及数组都要在堆上分配)。
java堆是垃圾收集器管理的主要区域,因此也被成为“GC堆”。
从内存回收角度来看java堆可分为:新生代和老年代。
从内存分配的角度看,线程共享的Java堆中可能划分出多个线程私有的分配缓冲区。
无论怎么划分,都与存放内容无关,无论哪个区域,存储的都是对象实例,进一步的划分都是为了更好的回收内存,或者更快的分配内存。
根据Java虚拟机规范的规定,java堆可以处于物理上不连续的内存空间中。当前主流的虚拟机都是可扩展的(通过 -Xmx 和 -Xms 控制)。如果堆中没有内存可以完成实例分配,并且堆也无法再扩展时,将会抛出OutOfMemoryError异常。
程序计数器
程序计数器(Program Counter)是 Java 运行时数据区中的一个较小但非常重要的部分,用于指示当前线程正在执行的字节码指令的地址。
是java内存模型中唯一没有OutOfMemoryError区域。
工作原理
当线程执行一个方法时,程序计数器会指向该方法的字节码的起始位置。随着方法的执行,程序计数器会不断更新,指向下一条要执行的字节码指令。如果该方法执行过程中发生了线程切换(例如被其他线程抢占了 CPU),当该线程重新获得执行机会时,程序计数器能让它准确地回到之前中断的位置继续执行。
特点
线程私有:每个线程都有自己独立的程序计数器,彼此之间互不影响。属于线程私有的内存
占用空间小:它所需的存储空间极小。
作用
保证线程执行连续性:确保线程能够按照正确的顺序和流程执行代码,不会因为各种情况(如中断、切换等)而迷失执行路径。
多线程协作基础:使得多个线程可以独立运行且互不干扰,各自的执行进度都能得到准确记录和恢复。
一个有趣的例子
小帅正在看电视
突然小帅的朋友打来电话,此时小帅暂停看电视,与朋友通话
电话结束,小帅接着看电视
CPU正在执行线程A的任务
线程B处于就绪态,CPU此时选择执行线程B的任务,挂起线程A
CPU执行完线程B的任务,继续切换回来继续执行线程A未完成的任务。(程序计数器的作用就在这儿,保证线程执行连续性、多线程协作的基础)
Java虚拟机栈
Java 虚拟机栈(Java Virtual Machine Stack)是 Java 虚拟机中用于存储方法调用和局部变量等信息的一种数据结构。
特点
线程私有:每个线程都有自己独立的 Java 虚拟机栈,它的生命周期和线程相同。
先进后出顺序:遵循先进后出的原则,保证了方法调用的正确顺序和逻辑。
栈结构

java虚拟机栈由一个个栈帧组成,栈帧用于存储方法调用的相关信息,包括局部变量表、操作数栈、动态链接、方法出口等。
虚拟机栈:定义了一个虚拟机栈的接口,包含了 push(栈帧) 方法表示将栈帧压入栈中,以及 pop() 方法表示弹出栈顶的栈帧。
栈针结构
局部变量表:用于存储方法中的局部变量,包括基本数据类型、对象引用地址和ReturnaddressType类型等。
ReturnaddressType类继承自“Type”类,目的是用于表示返回地址类型,在程序中可能用于处理或标识某种特定类型的返回地址。操作数栈:在方法执行过程中用于进行数据操作和运算。
动态链接:将符号引用转换为直接引用,以支持方法调用的动态绑定。
在 Java 程序运行时,当一个方法调用另一个方法时,可能并不知道被调用方法的具体内存地址。此时存在的只是一个符号引用,它包含了关于被调用方法的一些信息,比如方法所在的类、方法名等。随着程序的执行,在需要实际执行这个方法调用时,就需要通过动态链接来将这个符号引用解析为真正的直接引用,也就是确定该方法在内存中的具体位置。 动态链接使得 Java 能够实现动态绑定等特性,增强了程序的灵活性和扩展性。它在运行时根据实际的类和对象情况来确定具体调用的方法版本,从而支持多态等机制。这样,即使在运行时类的结构或关系发生了变化,也能够正确地进行方法调用和处理。
方法出口:记录方法执行完毕后要返回的位置,以便正确返回到调用该方法的地方。
当一个方法执行完毕后,程序需要知道接下来应该回到哪里继续执行。方法出口就记录了这个“返回的位置”。具体来说,当一个方法被调用并进入执行后,在栈帧中会记录下调用该方法的下一条指令的位置(比如在调用者方法中的位置)。当该方法正常结束(比如执行到方法的最后一行代码或者通过特定的返回语句结束),就会根据这个方法出口所记录的位置,跳回到调用者那里,继续从那个位置开始执行后续的代码。它确保了方法调用的流程能够正确地延续和返回,维持程序执行的连贯性和正确性。
本地方法栈
本地方法栈(Native Method Stack)与 Java 虚拟机栈类似,它也是线程私有的,主要用于支持 Native 方法(非 Java 语言编写的方法,如C、C++)的执行。
主要区别在于所服务的方法类型不同。Java 虚拟机栈主要服务于 Java 方法,而本地方法栈则专注于 Native 方法。
特点和作用
与本地方法关联:当线程调用本地方法时,相关的信息和数据会存储在本地方法栈中。
执行环境:为本地方法的执行提供了一个独立的运行环境和空间,用于管理本地方法执行过程中的状态、局部变量等。
跨语言支持:允许 Java 程序与其他语言编写的代码进行交互和协作,拓展了 Java 程序的功能和应用场景。
栈操作:也遵循先进后出的原则,记录本地方法的调用顺序和状态切换。
执行引擎
执行引擎是 Java 虚拟机的核心组成部分之一,主要负责将字节码转换为具体的机器指令并执行
结构
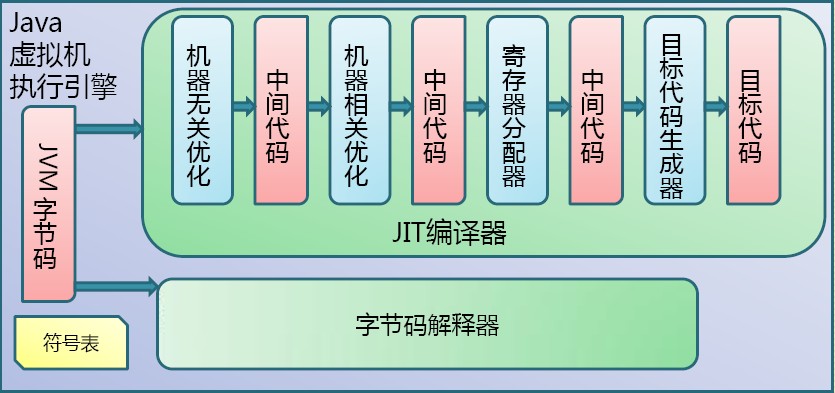
解释器
解释器是 Java 虚拟机中用于执行字节码的组件,它逐行读取字节码指令,并将其转换为具体的操作(本地机器指令)来执行。通过对字节码的解释执行,实现了 Java 程序的运行。
分类
字节码解释器:通过纯软件代码模拟字节码的执行,效率非常低
模板解释器::每一条字节码和一个模板函数相关联,模板函数能直接生产这条字节码执行时的机器码。
工作原理
按照字节码规范,对每一条字节码指令进行解析和处理。它理解指令的含义,然后执行相应的计算、数据操作、流程控制等动作。
优势
跨平台性:因为只需要解释字节码,而不需要针对特定硬件进行编译,所以能保证 Java 在不同平台上的一致性和可移植性。
启动速度相对较快:不需要进行复杂的编译过程,可快速开始执行程。
JIT编译器
分类
C1编译器(Client Compiler):C1编译器会对字节码进行简单和可靠的优化,耗时短,以达到更快的编译速度。
C2编译器(Server Compiler):C2编译器会进行更长时间的优化,采取更激进的优化策略,耗时长,编译后的代码执行效率更高。
可以通过命令来设置JVM运行时使用哪种JIT,但64位机器只能使用Server Compiler(C2编译器)。
-client 指定使用C1编译器
-server 指定使用C2编译器工作原理
热点探测:JIT 编译器会监测程序运行过程中哪些代码片段被频繁执行,这些被称为热点代码。
编译执行:一旦确定了热点代码,就会将其编译成本地机器代码,之后再执行这些代码时,就可以直接执行高效的本地机器代码,而无需再通过字节码解释器进行解释执行,从而大大提高了执行速度。
优化:在编译过程中,JIT 编译器还可以进行各种优化,如代码优化、指令重排等,以进一步提升性能。
优势
适应动态性:能根据程序实际运行情况针对性地进行编译和优化,更适合 Java 这种动态语言的特点。
性能提升:在热点代码上实现了比字节码解释器更高的执行效率。
工作方式
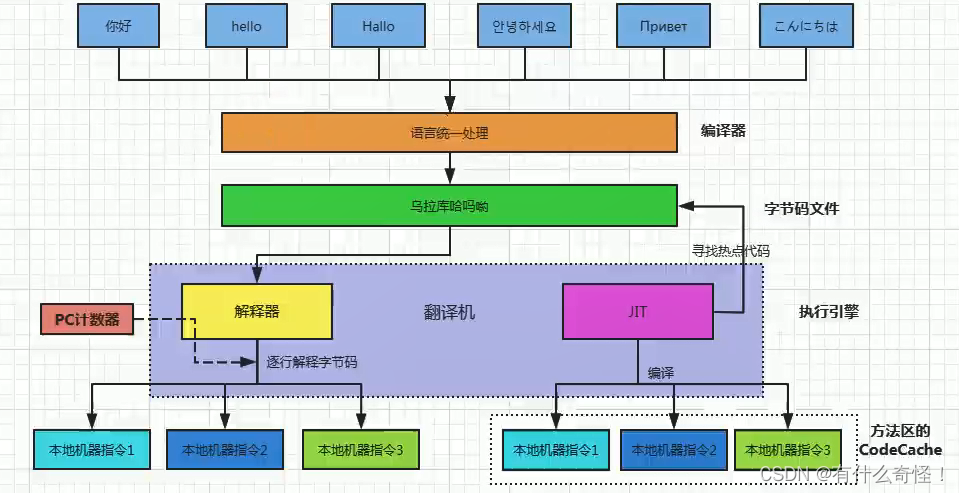
默认情况下,HotSpot VM采用解释器与JIT编译器并存的架构,开发者可以通过参数设置完全使用解释器或者完全使用JIT编译器。
-Xint 完全使用解释器来执行程序
-Xcomp 完全使用JIT编译器 如果编译出错 解释器会介入执行
-Xmixed 解释器+JIT编译器共同执行程序(默认)热点代码
热点代码是指在程序运行过程中被频繁执行的代码片段,直接决定该代码片段是否被JIT编译器编译。
JIT编译器在运行期间会对热点代码做出深度优化,并将其编译成机器指令缓存到方法区的Code Cache,以提升Java程序的执行性能。
热点代码判定次数C1是1500次,C2是10000次。
热点探测
基于计数器的热点探测:
hotspot vm正是基于计数器的热点探测
方法调用计数器:统计方法被调用的次数。当一个方法被调用达到一定次数时,就可能被视为热点。
回边计数器:主要针对循环,统计一个方法中循环代码块的执行次数。如果循环执行频繁,该部分代码就可能成为热点。
基于采样的热点探测:定期对程序运行状态进行采样,分析哪些代码片段被执行的频率较高。这种方式相对简单,但可能不够精确。
基于踪迹的热点探测:通过跟踪程序执行的具体踪迹来确定热点代码。这种方式能更准确地捕捉到执行频繁的代码路径,但实现起来可能更复杂。
本地接口库
本地接口库是一组由本地代码(通常是 C 或 C++)实现的接口,它允许 Java 代码与底层操作系统或硬件进行交互。
作用
提供对底层资源的访问
可以直接访问操作系统的功能,如文件系统操作、网络通信、图形处理等。
实现 Java 中无法直接实现的高性能操作。
与其他语言交互
使得 Java 能够调用用其他语言编写的库和程序,实现跨语言的集成。
例如,与 C/C++ 编写的高性能计算库进行交互。
工作原理
Java 代码中的本地方法声明
在 Java 代码中,可以使用native关键字声明一个本地方法。这个方法没有具体的实现,只是一个占位符,表示该方法将由本地代码实现。加载本地库
当 Java 程序运行时,JVM 会根据需要加载相应的本地接口库。这个过程通常是动态的,可以在运行时根据特定的条件加载不同的本地库。方法调用与执行
当 Java 代码调用一个本地方法时,JVM 会将控制权转移到本地接口库中的相应实现。本地代码执行完毕后,将结果返回给 Java 代码。
优点
性能提升:对于一些需要高性能的操作,使用本地接口库可以充分利用底层系统的优势,提高程序的执行效率。
灵活性:可以根据具体需求选择合适的本地库,实现特定的功能。
注意事项
平台依赖:本地接口库通常是针对特定的操作系统和硬件平台编写的,因此在不同的平台上可能需要不同的本地库。
安全性:由于本地代码可以直接访问底层系统,因此需要注意安全性问题,防止恶意代码的攻击。
维护成本:本地接口库需要用 C 或 C++ 等语言编写和维护,这可能增加开发和维护的难度。


评论区